测试

这里也是复现的一道misc题
就是脚本批量读取二维码数据,所以需要判断图片然后 扫描二维码
import os
import string
import image
from PIL import Image
import pyzbar.pyzbar as pyzbar
import os
def name(String):
imgs=[]
list =os.listdir(String)
for i in list:
ext=os.path.splitext(i)
if(len(ext)>1 and jpgimage(ext[1])):
imgs.append(i)
return imgs
#扫描批量的二维码
def qrcode_parse_content(img_path):
'''
单张图片的二维码解析
'''
img = Image.open(img_path)
# 使用pyzbar解析二维码图片内容
barcodes = pyzbar.decode(img)
# 打印解析结果,从结果上可以看出,data是识别到的二维码内容,rect是二维码所在的位置
# print(barcodes)
# [Decoded(data=b'http://www.h3blog.com', type='QRCODE', rect=Rect(left=7, top=7, width=244, height=244), polygon=[Point(x=7, y=7), Point(x=7, y=251), Point(x=251, y=251), Point(x=251, y=7)])]
result = []
for barcode in barcodes:
barcode_content = barcode.data.decode('utf-8')
result.append(barcode_content)
return result
def jpgimage(ext):
ext=ext.lower()
if(ext==".jpg") :
return True
if(ext==".gif"):
return True
if(ext==".png"):
return True
return False
print(name("C:\\Users\\c'x'k\\Desktop\\桌面壁纸"))
print(qrcode_parse_content("E:\\Tobby\\erwei.png"))
print(qrcode_parse_content("E:\\Tobby\\erwei.png")[0])
['bay.jpg', 'wallhaven-9mjoy1.png', 'wallhaven-l8kggq.jpg', 'Zero.png']
['JYcxk']
JYcxk
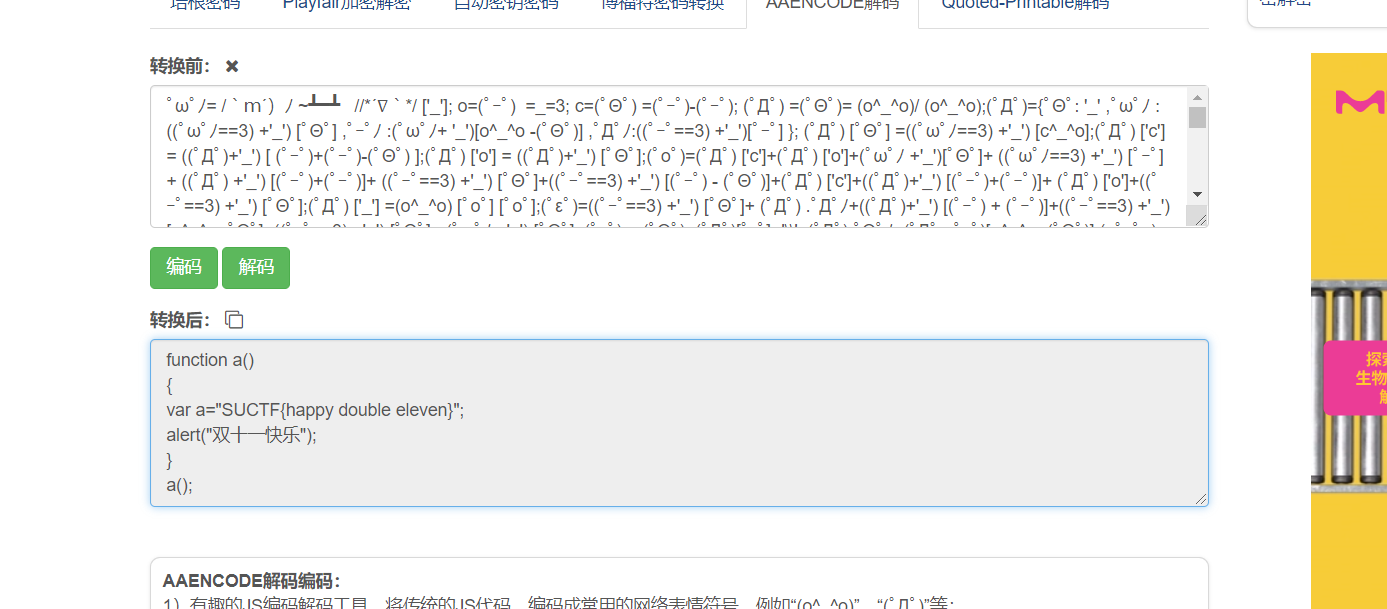
[SUCTF2018]single dog
一张图片010看见了txt直接分离
foremost att.jpg分离出一个 txt和zip
txt是aaencode,解密即可
sqltest
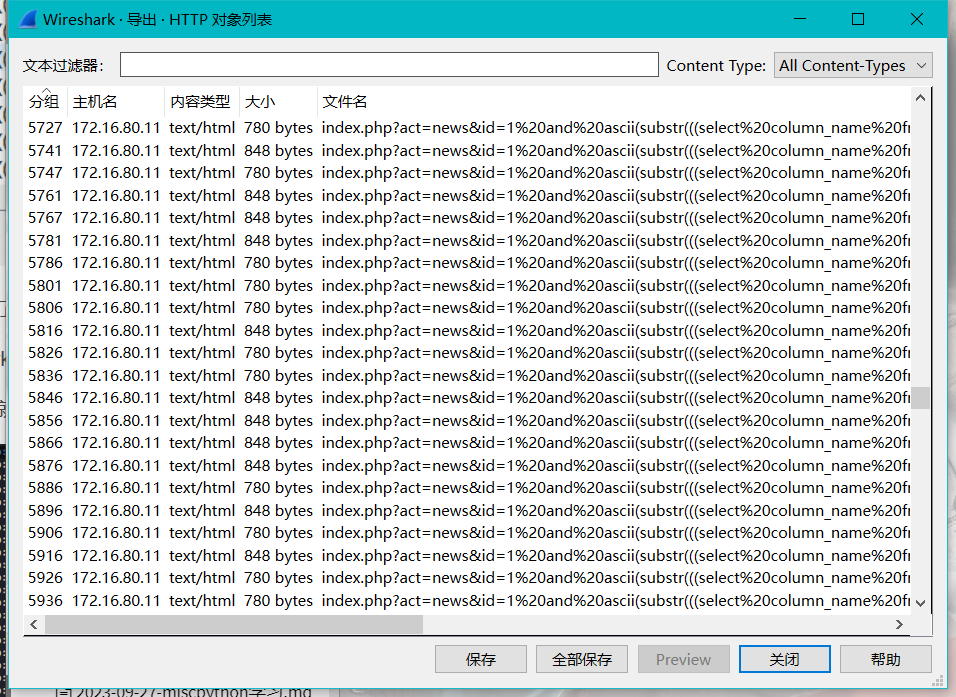
wireshark流量分析,是一个sql布尔盲注的流量分析
通过状态码就可以分析出来flag
学一下拿脚本怎么实现(首先就是如何保存下来需要用到tshark)
tshark在 安装wireshark的时候就是自带的,我本地在 D:\misc\sharkwhie\Wireshark位置
tshark -r sqltest.pcapng -Y "http.request" -T fields -e http.request.full_uri > data.txt
-r 读取文件
-Y 过滤语句
-T pdml|ps|text|fields|psml,设置解码结果输出的格式
-e 输出特定字段
http.request.uri http请求的uri部分
首先输出一下带上行号
with open("D:\\misc\\sharkwhie\\Wireshark\\data.txt","r") as file:
line_num=1
for line in file:
print(f"{line_num}:{line.strip()}")
line_num=line_num+1
发现了一种遍历行更简单的脚本
import urllib.parse
f = open("D:\\misc\\sharkwhie\\Wireshark\\data.txt","r").readlines()
s = []
for i in range(627,972):
data = urllib.parse.unquote(f[i]).strip()
print(data)

从628行开始就是盲注字段的内容了,然后可以发现每次测位置的最后一个为真正的值,所以我们写脚本
1,1
2,1这种瞬间即可
为了简单分为二个脚本
这个脚本会报错因为最后一个会越界for循环
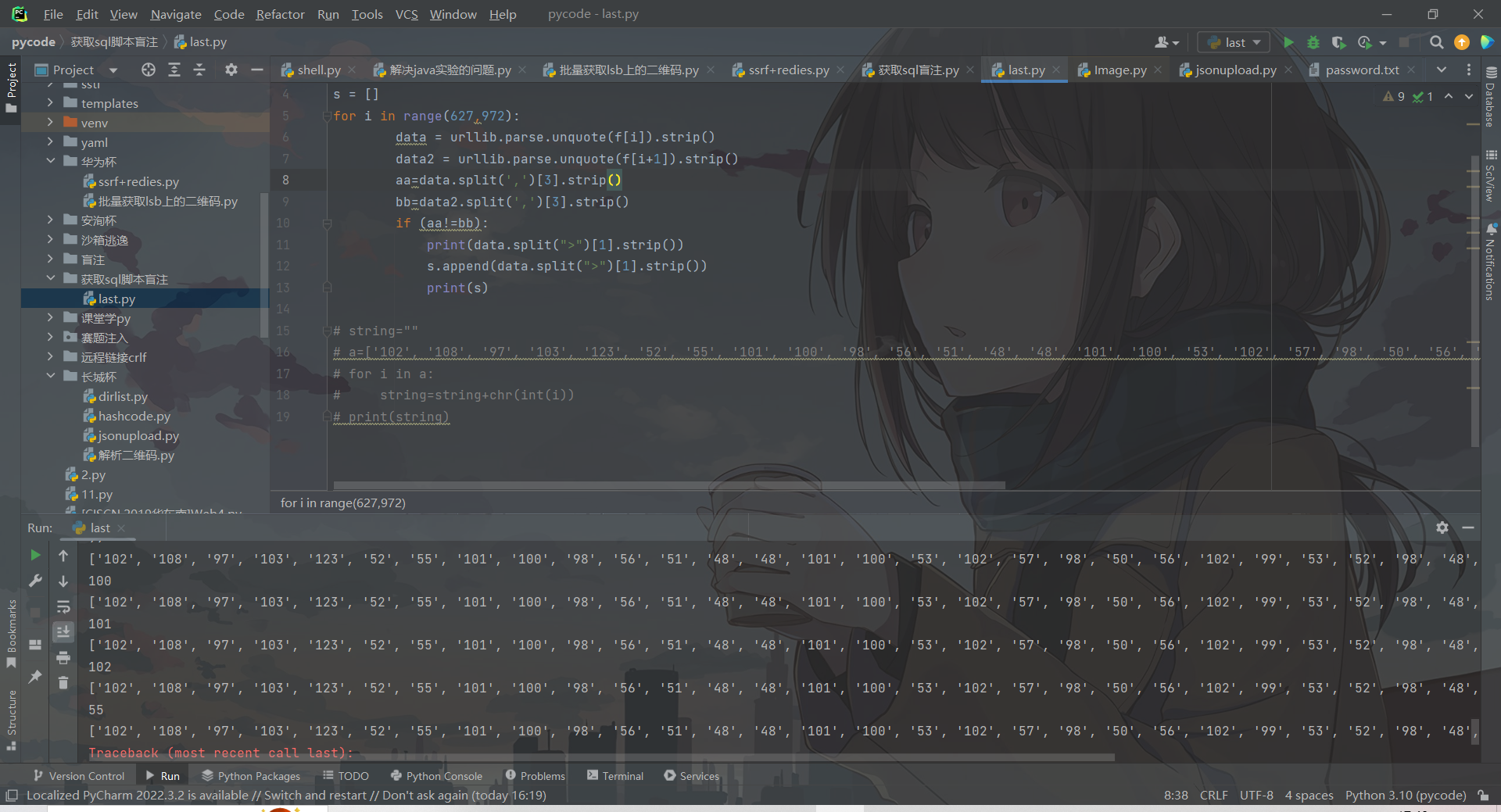
import urllib.parse
f = open("D:\\misc\\sharkwhie\\Wireshark\\data.txt","r").readlines()
s = []
for i in range(627,972):
data = urllib.parse.unquote(f[i]).strip()
data2 = urllib.parse.unquote(f[i+1]).strip()
aa=data.split(',')[3].strip()
bb=data2.split(',')[3].strip()
if (aa!=bb):
print(data.split(">")[1].strip())
s.append(data.split(">")[1].strip())
print(s)
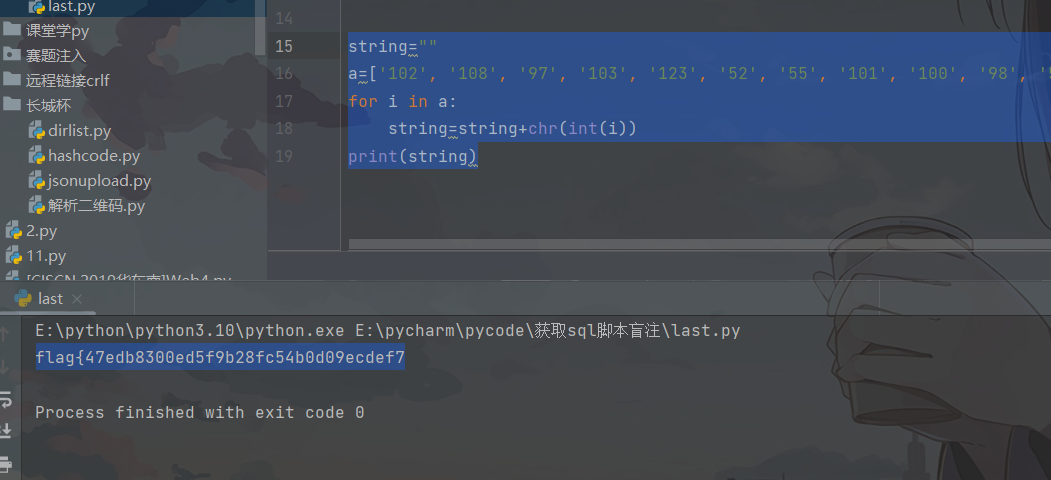
这里需要注意的是记得 转int不然会报错 chr (int(i)) (自己加个括号即可)
string=""
a=['102', '108', '97', '103', '123', '52', '55', '101', '100', '98', '56', '51', '48', '48', '101', '100', '53', '102', '57', '98', '50', '56', '102', '99', '53', '52', '98', '48', '100', '48', '57', '101', '99', '100', '101', '102', '55']
for i in a:
string=string+chr(int(i))
print(string)
[ACTF新生赛2020]NTFS数据流
打开之后是n个txt文件

用这个软件即可直接扫出来

[ACTF新生赛2020]swp
一个流量包
导出http对象,发现secret.zip
喵喵喵
开局一张图片,直接lsb
这里没太理解,分为BGR信道,只有这个信道里面有图片

保存下来以后,直接save bin然后修改开头为
89504E47 尾部 IEND即可,然后发现是一张一半的二维码
改一下宽高即可

扫描二维码
下载一个flag.rar,解压是一段文本
flag不在这里

本作品采用CC BY-NC-ND 4.0进行许可。转载,请注明原作者 Azeril 及本文源链接。